| Node | | Mise à jour 11-2014 |
|
Node est un environnement qui permet d'écrire en javascript côté serveur des applications web. Je l'ai donc étudié d'une manière pratique en réalisant une application simple. Cette démarche a l'avantage de se confronter à des problèmes réels et de permettre de trouver des solutions concrètes. Node est de bas niveau, ce qui nécessite de prendre en charge beaucoup d'opérations normalement gérées par des outils plus évolués. Il ne faut pas attendre de lui d'aide à la conception des bases de données (comme dans Rails à nouveau); ne pas oublier d'envoyer les entêtes html etc... Il est cependant extensible à travers de nombreux frameworks ou modules (base de données, gestion de vues, routage ...), que l'on incorpore avec une instruction require. J'ai choisi ici de l'utiliser avec ses fonctions de base. La désynchronisation L'avantage est qu'il est très rapide en exécution et qu'il sait mener des tâches en parallèle, désynchronisées, grâce au moteur javascript embarqué. Ce parallélisme, bénéfique pour gérer des nombreuses demandes simultanées sur un serveur, pose cependant problème. Typiquement, les accès base de données sont des opérations "longues" et désynchronisées. Ce qui signifie que la requête est envoyée au serveur de base de données ensuite l' exécution de la fonction continue, sans attendre la fin de la requête. Au sein d'une page html, la difficulté est donc de synchroniser l'ensemble des accès base de données avec la constitution des pages html, qui doit attendre que tous les accès soient terminés. Ceci est résolu par le mécanisme de callback qui permet d'éxécuter une fonction lorsqu'une action désynchronisée se termine enfin. Ainsi au lieu d'écrire "classiquement" :
Les modules L'organisation d'un projet est entièrement libre. On a cependant avantage à découper l'application en différents modules afin de faciliter leur écriture et leur maintenance. Des frameworks spécifiques peuvent proposer des organisations particulières. Un module est composé de fonctions. Pour les rendre publiques, c'est-à-dire appelables par d'autres modules, il faut les exporter. Sinon elle restent d'usage interne au module. Le nom exporté n'est pas obligatoirement le même que le nom réel. Par exemple, la fonction nommée myproc peut s'exporter sous le nom ma_procedure. |
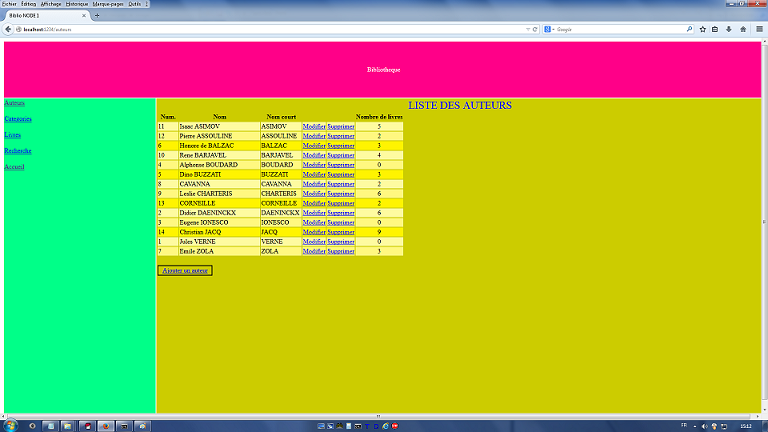
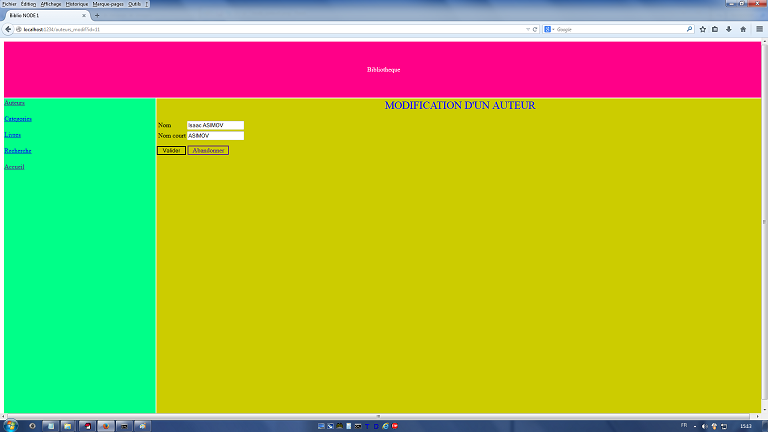
L'exemple proposé ici est une classique application de bibliothèque. Il est organisé autour de 3 tables : des auteurs, des catégories et des livres. Un livre appartient à un auteur et est défini par sa catégorie. L'écran est structuré également de manière classique, avec un bandeau horizontal pour le titre, un bandeau vertical à gauche pour le menu et une partie centrale recevant les différents formulaires. Eux-mêmes sont organisés toujours de manière identique : un titre, un corps et un pied de page regroupant les boutons d'action. Il existe deux types de formulaires :
Exemples de pages :
Une application Node commence par la création d'un serveur HTTP. On doit associer à celui-ci un n° de port et une fonction de callback qui a pour but d'interpréter la requête reçue. Cette opération s'appelle le routage. En fonction de l'url demandée, le routeur appelle la fonction associée. La plupart des fonctions reçoivent deux paramètres particuliers, request et response, qui comportent les objets représentant la requête au navigateur et la réponse qui lui est envoyée. Par simplification, les chemins d'accès des fichiers et modules sont indiqués "en dur".
Les répertoires sont organisés de la manière suivante. Le répertoire principal contient les modules généraux de l'application. Il contient aussi deux répertoires dont l'utilisation est parallèle :
Les chapitres suivants présentent les fichiers de chaque répertoire, dans l'ordre alphabétique, avec une explication succinte de leur conception et de leur contenu. Chaque fichier contient des commentaires participant à la compréhension du code.
Le répertoire principal contient les fichiers suivants. accueil.js Constitution de la page d'accueil du site. Cette page est statique. basedonnees.js Contient une fonction qui ouvre la connexion à la base de données. La base est Sqlite3. development.sqlite3 La base de données. index.js La page de démarrage du site. On la lance par une commande node index.js. Elle démarre le serveur http et lui affecte la fonction de routage. En paramètre, la table de routage qui fait le lien entre l'url et le nom des fonctions à appeler. Pour la gestion des différentes tables de la base, il existe des modules différents, référencés par des instructions require. Ensuite, dans le navigateur, la page d'accueil s'obtient par localhost:1234. 1234 est le n° de port ataché au serveur http. presentation.js Ce fichier contient plusieurs fonctions générales destinées à finaliser la constitution des pages html.
Ce fichier contient la fonction de routage qui recherche l'existence du lien entre l'url demandée et la fonction de traitement. S'il existe, la fonction est activée sinon une page d'erreur 404 est envoyée. server.js Démarre le serveur sur un n° de port particulier (1234 a été choisi). Un callback extrait le nom de la page de l'url et appelle la fonction de routage pour exécution de la fonction associée.
Ces deux répertoires fonctionnent en parallèle; à un fichier dans les controleurs correspond un fichier dans les vues, suffixé par _vues. auteurs.js et auteurs_vues.js Le controleur possède une fonction de liste qui présente les auteurs existants, un par ligne, avec un lien modifier, un lien supprimer sur chacune, et un lien ajouter en bas de page. Elle est architecturée autour de la fonction each de l'objet de base de données, qui possède deux fonctions de callback:
Lors de la demande de modification par exemple, un objet nommé xrow est créé, qui comportera les données de la base. Cet objet est transmis à la vue qui reporte ces données dans le formulaire. Lors de la validation du formulaire, les données sont envoyées en POST et immédiatement remises dans un nouvel objet xrow. De sorte que si les contrôles de validité acceptent les valeurs, il suffit de les transférer de l'objet xrow à la base de données (un run accompagné d'un callback qui réaffiche la liste). En cas d'erreur, il suffit de réactiver l'affichage de la page à partir de l'objet xrow, auquel on a ajouté le message d'erreur. La suppression fait appel à une fonction javascript côté navigateur. Celle-ci lance une demande de confirmation puis, si la réponse est "ok", redirige le navigateur sur la fonction de validation de la suppression. Cette dernière supprime la ligne puis, dans un callback, réaffiche la liste. La contrainte est que le navigateur permette l'exécution de scripts. categories.js et categories_vues.js Le principe est le même que pour les auteurs. general.js et general_vues.js Ce module regroupe des fonctions utilisées plusieurs fois dans l'application. Il s'agit du chargement des listes déroulantes auteurs et catégories, utilisées dans l'ajout/modification d'un livre, mais aussi dans les critères de recherche des livres. Leur conception ressemble à celle de la gestion des tables auteurs et catégories; la différence essentielle vient d'un paramètre supplémentaire callback qui permet d'enchainer les fonctions entre elles suivant les cas d'utilisation. livres.js et livres_vues.js Le controleur possède une fonction de liste, similaire à celle de la table des auteurs. Sa particularité est la récupération de cookies dans les données postées, afin d'appliquer des critères de recherche. Les cookies permettent de conserver des données entre plusieurs transactions, dans une même session. Les fonctions d'ajout et de modification sont un peu plus compliquées, car le mécanisme utilisé pour les auteurs ne suffit pas (les seules données de la table). Il faut aussi recharger les listes déroulantes, notamment dans le cas d'affichage d'anomalie. Pour cettre raison, on crée un objet xparams (semblable à xrow des auteurs) qui comportera toutes les données nécessaires : la connexion à la base, les listes déroulantes, les données du livre. Il est transmis entre les différentes fonctions et complété/modifié. Le traitement consiste à appeler une première fonction qui charge les données du livre et, dans son callback final, appelle le chargement de la liste déroulante des auteurs. Celle-ci charge la liste des auteurs et, dans son callback final, appelle le chargement de la liste déroulante des catégories. Celle-ci charge la liste des catégories et, dans son callback final, affiche le formulaire. Comme le chargement des listes et l'affichage sont utilisés à plusieurs endroits dans le contrôleur, une fonction a été dédiée afin de ne pas répéter le code. La fonction de suppression est similaire à celle des auteurs. recherche.js et recherche_vues.js Ce module fonctionne un peu comme le module des livres, à l'exception du fait que les données résultantes de ce formulaire ne sont pas stockées dans une base de données mais dans des cookies. |
Quelques modules supplémentaires à charger avec npm, non livrés en standard, sont nécessaires. Modifier les chemins d'accès (X:/...) dans les fichiers.js. sqlite3 cookies
Ces quelques sites proposent des cours et documentations sur node. Openclassrooms Pour débuter Documentation technique détaillée sur les classes offertes Utilisation de la base de données sqlite |